os-用户态函数栈与内核态函数栈如何串起来
Contents
在程序执行过程中一旦系统调用就进入内核继续执行,那如何将用户态执行和内核态执行串起来的呢?
这个需要struct thread_info thread_info; void *stack;两个变量。
用户函数栈
在用户态函数调用是通过栈来实现的,即都在进程内存中栈中。在进程的内存空间里面,栈是一个从高地址到低地址,往下增长的结构,也就是上面是栈底,下面是栈顶,入栈和出栈的操作都是从下面的栈顶开始的。
32位系统
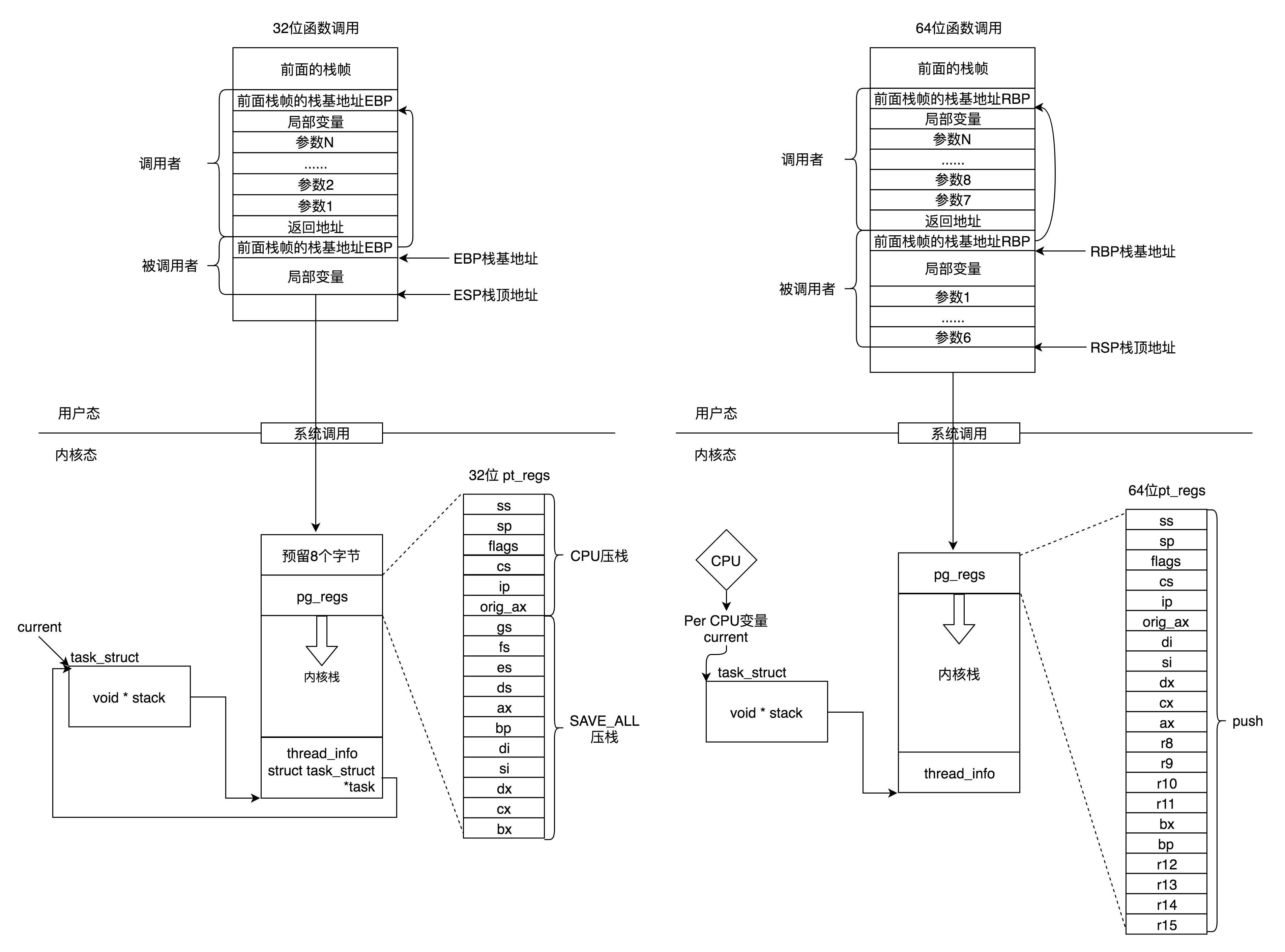
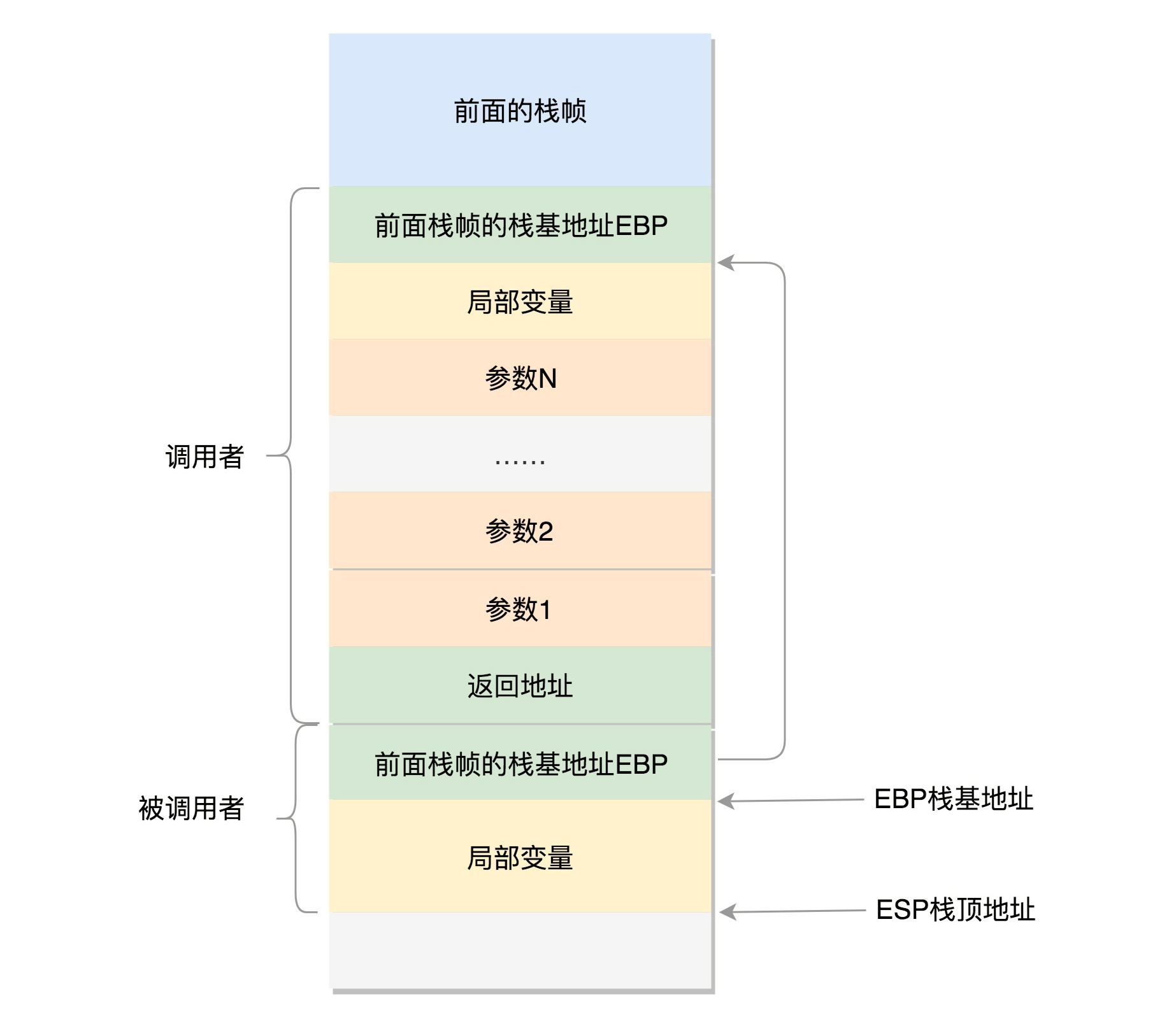
在32 位操作系统的情况。在 CPU 里,ESP(Extended Stack Pointer)是栈顶指针寄存器,入栈操作 Push 和出栈操作 Pop 指令,会自动调整 ESP 的值。另外有一个寄存器EBP(Extended Base Pointer),是栈基地址指针寄存器,指向当前栈帧的最底部。
64位系统
对于 64 位操作系统,模式多少有些不一样。
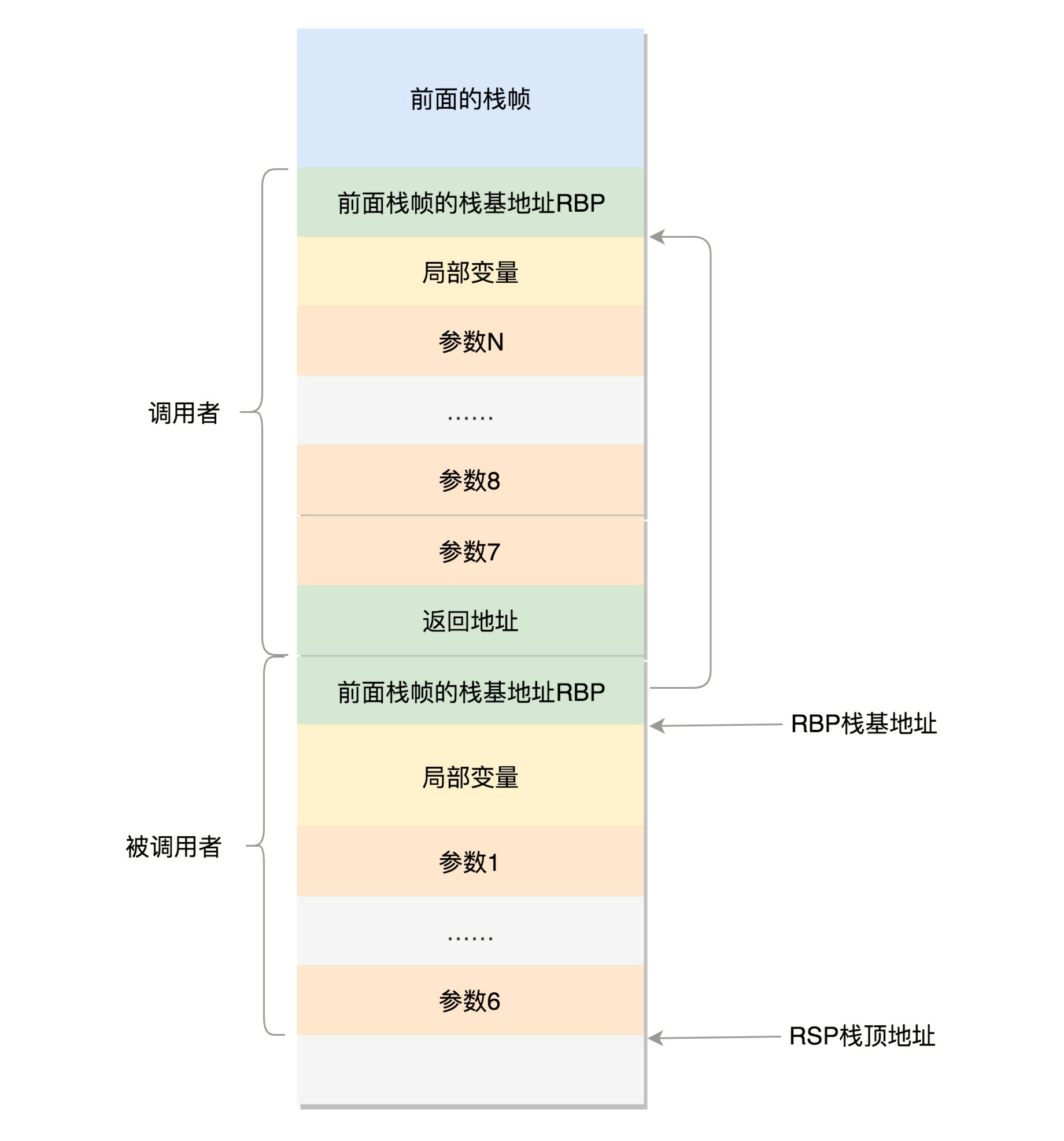
因为 64 位操作系统的寄存器数目比较多。rax 用于保存函数调用的返回结果。栈顶指针寄存器变成了 rsp,指向栈顶位置。堆栈的 Pop 和 Push 操作会自动调整 rsp,栈基指针寄存器变成了 rbp,指向当前栈帧的起始位置。
改变比较多的是参数传递。rdi、rsi、rdx、rcx、r8、r9 这 6 个寄存器,用于传递存储函数调用时的 6 个参数。如果超过 6 的时候,还是需要放到栈里面。
然而,前 6 个参数有时候需要进行寻址,但是如果在寄存器里面,是没有地址的,因而还是会放到栈里面,只不过放到栈里面的操作是被调用函数做的。
内核函数栈
接下来,通过系统调用,从进程的内存空间到内核中了。内核中也有各种各样的函数调用来调用去的,也需要这样一个机制,这该怎么办呢?
这时候,进程数据结构中的成员变量 stack,也就是内核栈,就派上了用场。
32位系统
Linux 给每个 task 都分配了内核栈。在 32 位系统上 arch/x86/include/asm/page_32_types.h,是这样定义的:一个 PAGE_SIZE 是 4K,左移一位就是乘以 2,也就是 8K。
1 | #define THREAD_SIZE_ORDER 1 |
64位系统
内核栈在 64 位系统上 arch/x86/include/asm/page_64_types.h,是这样定义的:在 PAGE_SIZE 的基础上左移两位,也即 16K,并且要求起始地址必须是 8192 的整数倍。
1 | #ifdef CONFIG_KASAN |
内核栈是一个非常特殊结构,如下图: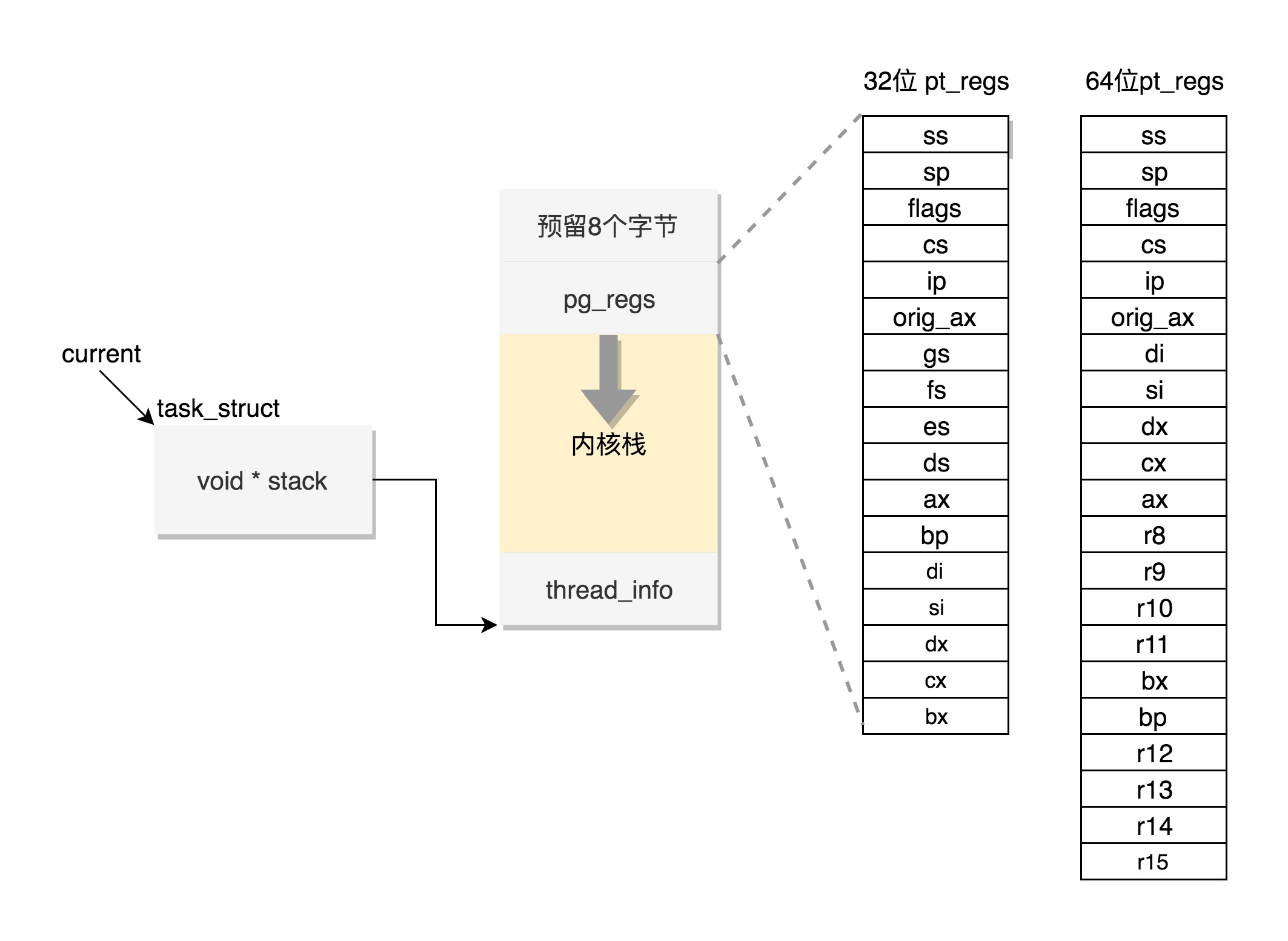
这段空间的最低位置,是一个 thread_info 结构。这个结构是对 task_struct 结构的补充。因为 task_struct 结构庞大但是通用,不同的体系结构就需要保存不同的东西,所以往往与体系结构有关的,都放在 thread_info 里面。
在内核代码里面有这样一个 union,将 thread_info 和 stack 放在一起,在 include/linux/sched.h 文件中就有,这个union的开头是thread_info,结尾是stack.
在内核栈的最高地址端,存放的是另一个结构 pt_regs,其中,32 位和 64 位的定义不一样,看图中pt_regs。
当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的 CPU 上下文保存起来,其实主要就是保存在这个结构的寄存器变量里。这样当从内核系统调用返回的时候,才能让进程在刚才的地方接着运行下去。
在内核中,CPU 的寄存器 ESP 或者 RSP,已经指向内核栈的栈顶,在内核态里的调用都有和用户态相似的过程。
这里64位系统的系统调用过程图,整体过程如下: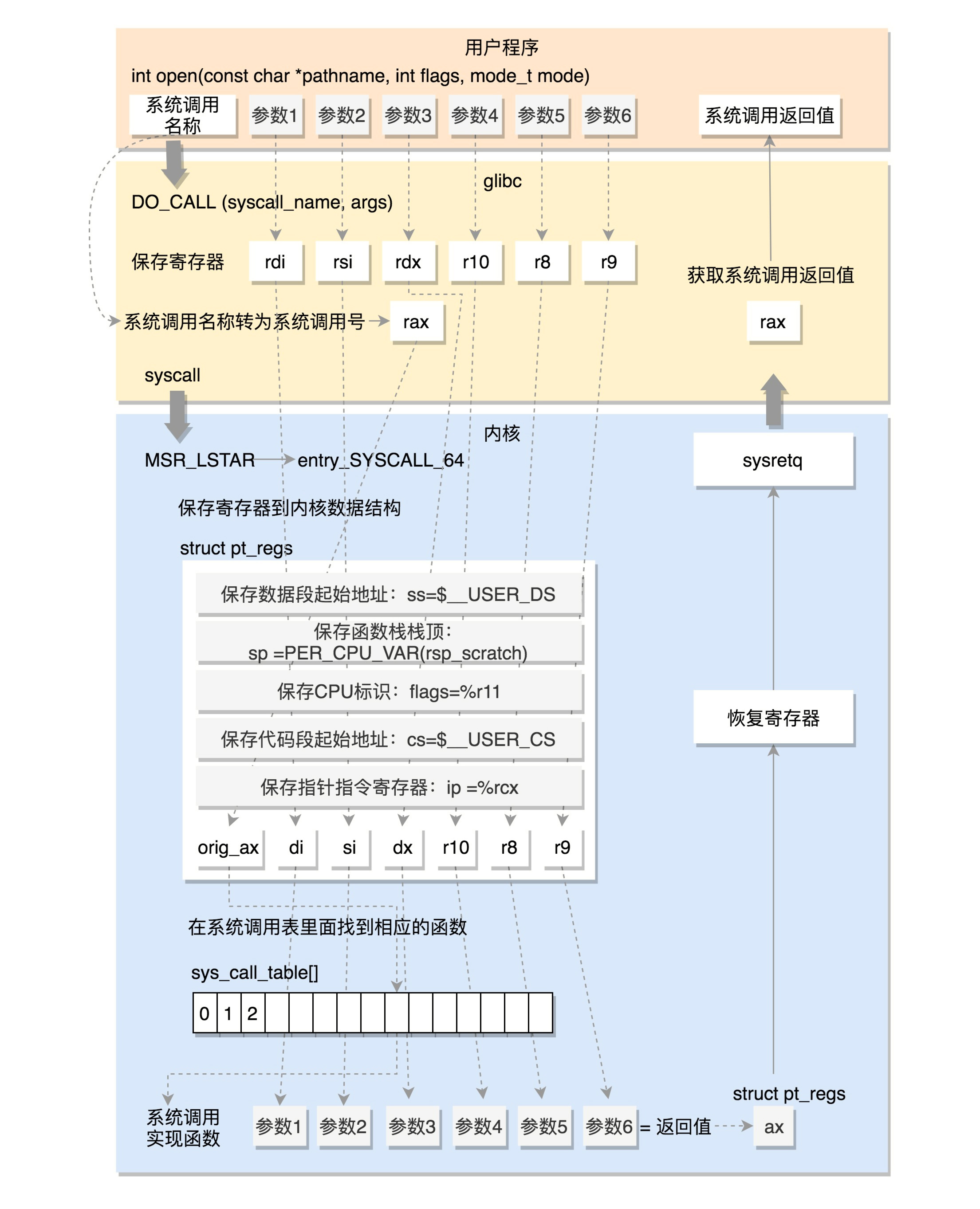
任务task_struct和内核栈如何相互定位
栈都是从高地址到低地址增长,上面是栈底,向下增长。
一个进程进入内核以及从内核返回出来的过程是如何的呢?
task_struct找到内核栈和内核寄存器
任务的结构体task_struct里保存着stack指针,通过指针可以找到内核栈。
从task_struct如何得到相应的 pt_regs 呢?
这是先从 task_struct 找到内核栈(高地址在上)的开始位置(即栈顶)。然后这个位置加上 THREAD_SIZE 就到了最后的位置,然后转换为 struct pt_regs,再减一,就相当于减少了一个 pt_regs 的位置,就到了这个结构的首地址。
内核内运行着task_struct结构体
32位系统内:
这个艰巨的任务要通过 thread_info实现的,结构体里面的有个成员变量 task 指向 task_struct。所以常用current_thread_info()->task 来获取 task_struct。
而 thread_info 的位置就是内核栈的最高位置,减去 THREAD_SIZE,就到了 thread_info 的起始地址。
64位系统内:
新的机制里面,每个 CPU 运行的 task_struct 不通过 thread_info 获取了,而是直接放在 Per CPU 变量里面了。
Per CPU 变量是内核中一种重要的同步机制。顾名思义,Per CPU 变量就是为每个 CPU 构造一个变量的副本,这样多个 CPU 各自操作自己的副本,互不干涉。比如,当前进程的变量 current_task 就被声明为 Per CPU 变量。
也就是说,系统刚刚初始化的时候,current_task 都指向 init_task。
当某个 CPU 上的进程进行切换的时候,current_task 被修改为将要切换到的目标进程,需要直接调用获取了。
总结
总结一下 32 位和 64 位的工作模式,左边是 32 位的,右边是 64 位的。 * 在用户态,应用程序进行了至少一次函数调用。32 位和 64 的传递参数的方式稍有不同,32 位的就是用函数栈,64 位的前 6 个参数用寄存器,其他的用函数栈。
- 在内核态,32 位和 64 位都使用内核栈,格式也稍有不同,主要集中在 pt_regs 结构上。
- 在内核态,32 位和 64 位的内核栈和 task_struct 的关联关系不同。32 位主要靠 thread_info,64 位主要靠 Per-CPU 变量。