redis-字典
定义
1 | typedef struct dictEntry { // 哈希节点 |
结构图:
字典也是redis键值对的结构,即数据库底层的实现。
哈希算法
1 | // 定义 |
redis使用MurmurHash2算法来计算键的hash值,这个算法的优点在于即使输入的键有规律,也能给出一个很好的随机分布性;
MurmurHash2算法
解决冲突
redis的哈希表使用链地址法来解决键冲突,新加入的节点会添加到链表的表头,排在其他所有节点的前面。
rehash算法
rehash步骤:
- 使用地点的ht[1]作为备份进行扩容或收缩空间
- 扩容和收缩时,ht[1]的大小大于等于ht[0].used
*2的2^n(2的n次方幂)
1.执行扩容前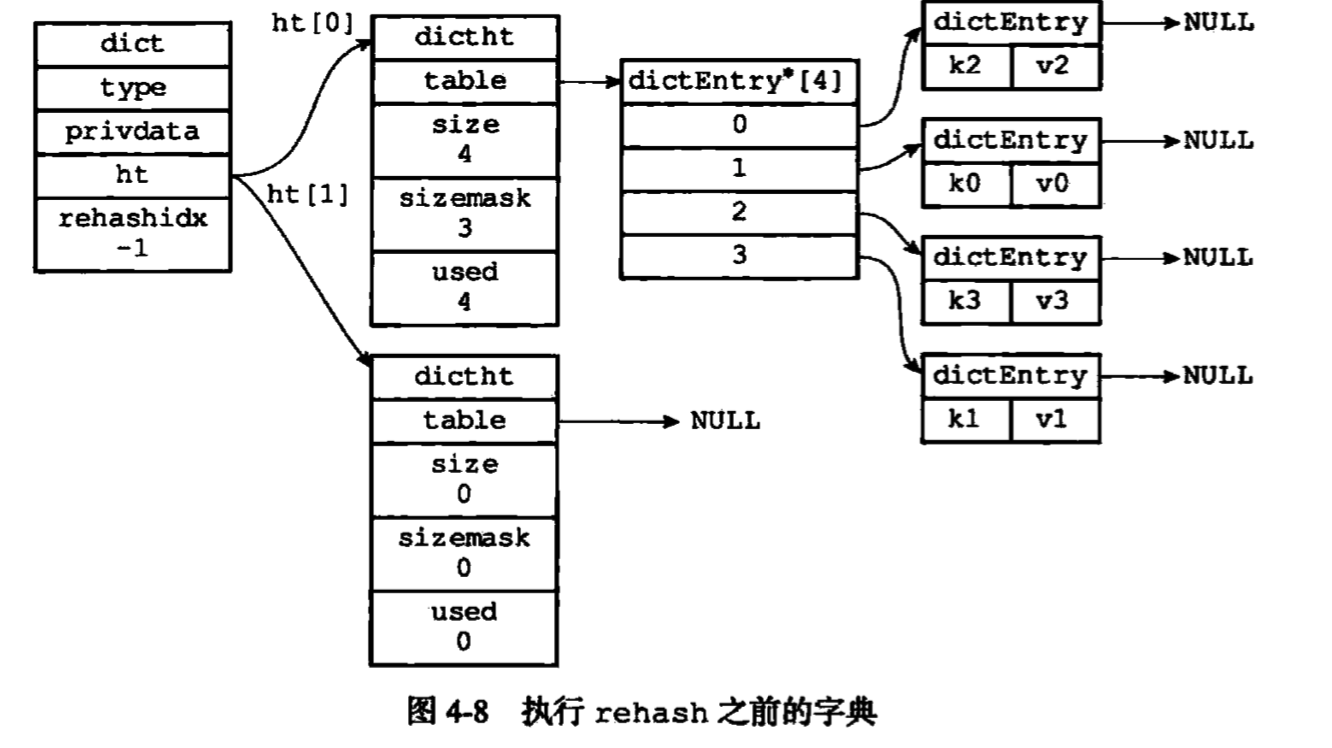
2.扩容时分配空间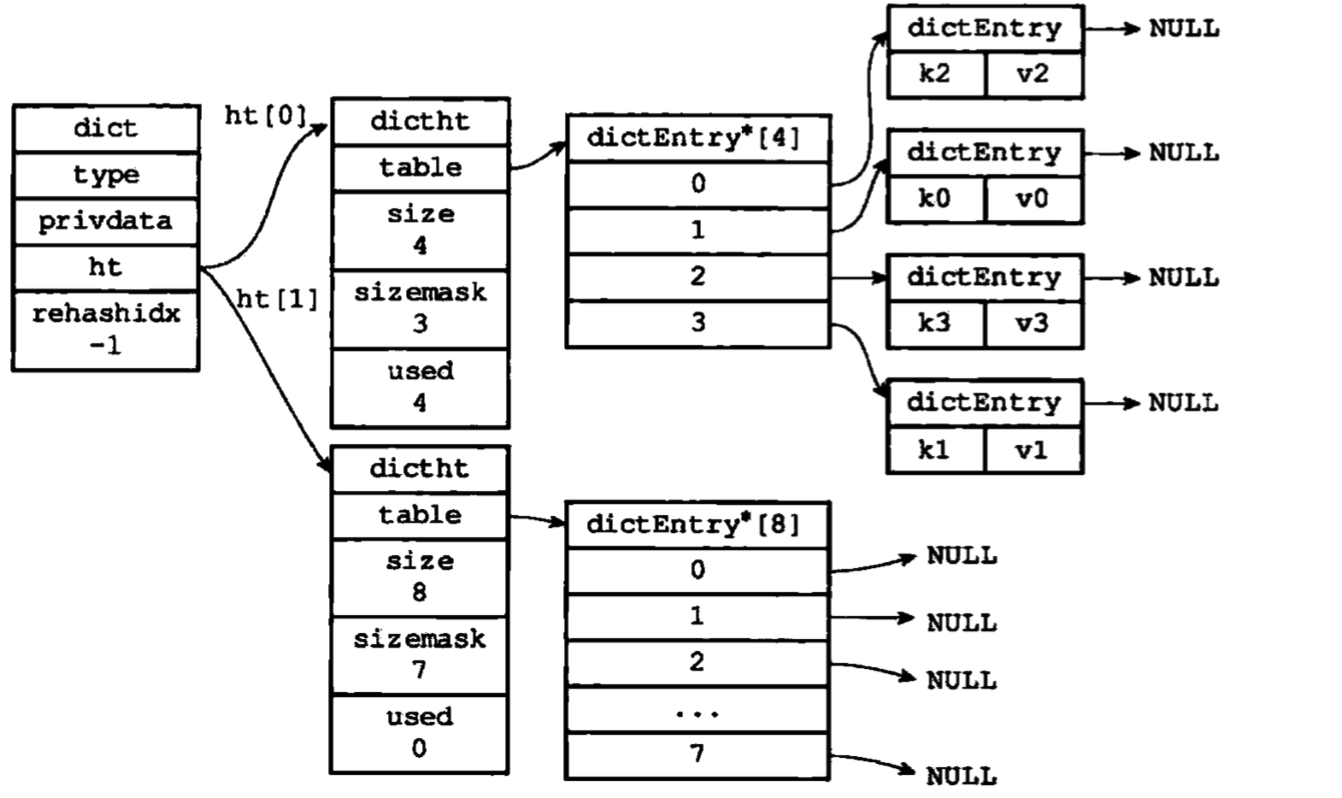
3.迁移节点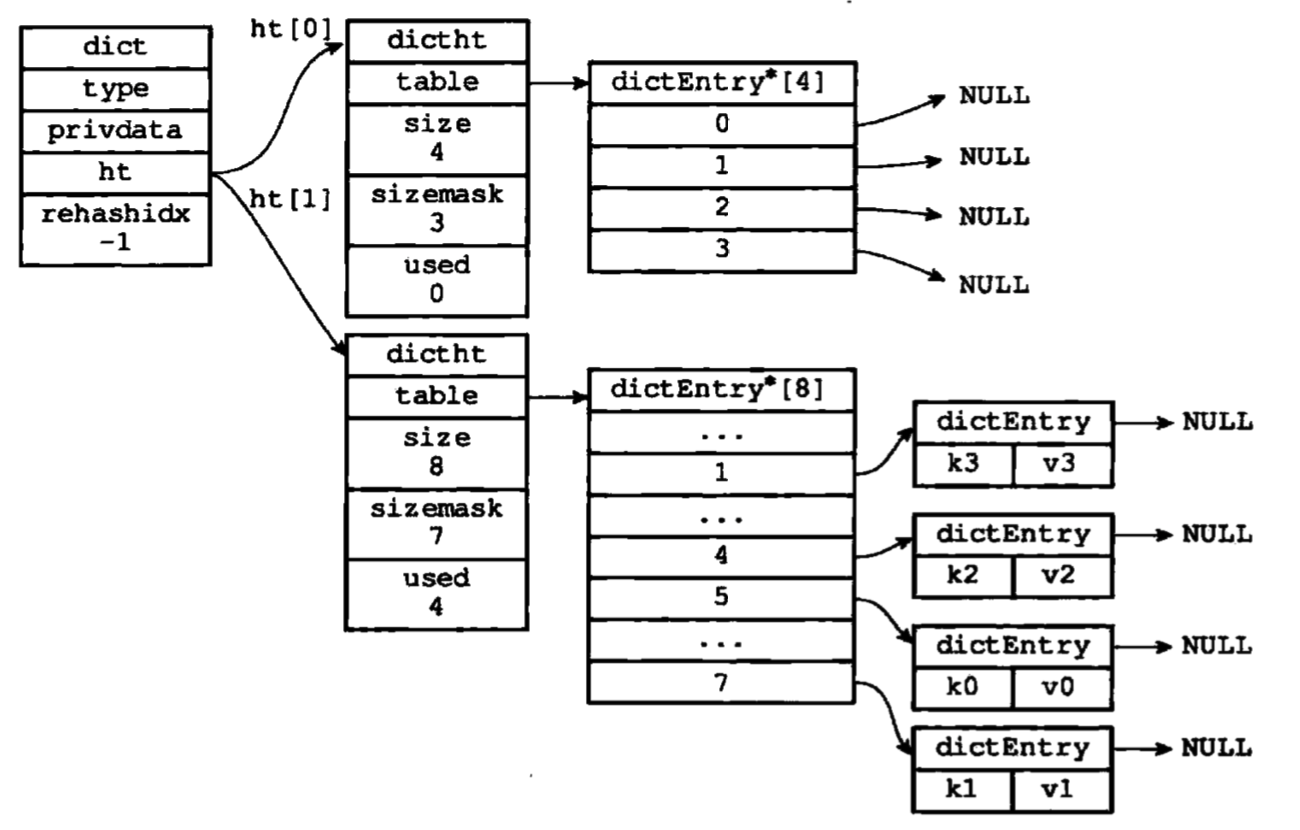
哈希表的扩容与收缩
以下条件任意一个被满足,就会执行扩容:
- 没有执行BGSAVE或BGREWRITEAOF命令,hash表的负载因子大于等于1
- 正在执行BGSAVE或BGREWRITEAOF命令,hash表的负载因子大于等于5
负载因子计算公式:load_factor = ht[0].used/ht[0].size 即,负载因子 = 哈希表已保存节点数量/哈希表大小;
当哈希表的负载因子小于0.1时,程序自动开始对hash表进行收缩操作;
rehash动作并不是一次性、集中式完成的,而分多次、渐进式地完成的。
更多源码注释说明见dict.h(https://github.com/dalaizhao/redis/tree/feature_code_comment)[https://github.com/dalaizhao/redis/tree/feature_code_comment]