JDK1.8 String源码解析
Contents
JDK源码深揪,JDK1.8版本。
摘要
经常用到的String类,不可变字符串,看看它是如何高效的处理字符串操作的。
== 和 equals()
== ,判断的是对象的内存起始地址是否相同;equals ,判断字符串内容是否相同。
常量池
在class文件中存在一个常量池,里面主要放字面量和符号引用,就是String s=”123”作为字符串字面量就在里面;而方法区中有一个常量池 叫做 运行时常量池,方法去外有一个常量池叫做字符串常量池(与方法区平级),字符串常量池是全局共享,类似缓存区。当加载class文件时,class文件中的常量池中大部分进入运行时常量池,但是 new String(”123“),中的”123“,是”进入”字符串常量池,这个进入为什么要加引号呢,最上面已经说了,字符串本身是在堆中(和其他一般对象一样,刚出来的时候很大可能是在eden中),然后在字符串常量池中有指向它的引用。
String.intern()会把String放在运行时的常量池。
为什么要有 常量池
- 字符串的分配,和其它的对象分配一样,消费高昂的时间和空间代价,作为最基础的数据类型,大量的频繁的创建字符串,极大程度影响程序的性能。
- JVM 为了提高性能和减少内存的开销,在实例化字符串常量的时候进行了一些优化
- 为字符串开辟一个字符串常量池,类似于缓存区
- 创建字符串常量时,首先判断字符串常量池是否存在该字符串
- 存在的话,返回引用实例,不存在,实例化该字符串并放入池中
- 实现的基础
- 实现该优化的基础是因为字符串不可变,可以不用担心数据冲突进行共享
- 运行时实例创建的全局字符串常量池中有一个表,总是为池中每个唯一的字符串对象维护一个引用,这就意味着它们一直引用着字符串常量池中的对象,所以,在常量池中的这些字符串不会被垃圾收集器回收。
在哪里 常量池
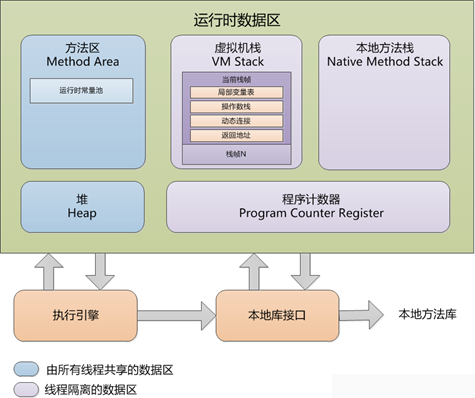
- 堆
- 存储的是对象,每个对象都包含一个与之对应的class。
- JVM只有一个堆区(heap)被所有线程共享,堆中不存放基本类型和对象引用,只存放对象本身
对象的由垃圾回收器负责回收,因此大小和生命周期不需要确定。
- 栈
- 每个线程包含一个栈区,栈中只保存基础数据类型的对象和自定义对象的引用(不是对象)。
- 每个栈中的数据(原始类型和对象引用)都是私有的。
- 栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令)。
- 数据大小和生命周期是可以确定的,当没有引用指向数据时,这个数据就会自动消失。
- 方法区
- 静态区,跟堆一样,被所有的线程共享。
- 方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
运行时常量池存在于方法区,而字符串常量池在非堆空间(但不是静态区)
1 | String str1 = “abc”; |
这个,这样理解:
对于new String("abc"),在执行new时,字符串常量池如果存在abc,则在堆创建对象new String(),并且把字符串常量池”abc”的引用返回给堆的对象, 不存在”bc11”,则在堆空间创建完对象再把内容写进字符串常量池。
String.intern()
当一个String实例str调用intern()方法时,Java查找运行时常量池中是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在运行时常量池中增加一个Unicode等于str的字符串并返回它的引用。
1 | String s0 = "k先生"; |
输出
1 | false |
源码解析
声明
声明为final,可序列化,可比较,不可变,不能被继承,实现了Serializable,Comparable,CharSequence接口。
1 | public final class String |
内部使用了final字符数组进行存储,涉及value数组的操作都使用了拷贝数组元素的方法,保证了不能在外部修改字符数组,String重写了Object的hashCode()方法使hash值基于字符数组内容,但是由于String缓存了hash值,所以即使通过反射改变了字符数组内容,hashCode()返回值不会自动更新。
1 | private final char value[]; |
构造方法
基本有14个公共构造方法,重载了很多:
- String类主要提供了通过String,StringBuilder,char数组,int数组,byte数组(需要指定编码)进行初始化。
- 通过字符数组,StringBuffer,StringBuilder进行初始化时,就要执行value数组元素的拷贝,创建新数组,防止外部对value内容的改变。
- 通过byte数组进行初始化,需要指定编码,或使用默认编码(ISO-8859-1),否则无法正确解释字节内容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66public String() {
this.value = new char[0];
}
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
public String(char value[], int offset, int count) {
if (offset < 0) {
throw new StringIndexOutOfBoundsException(offset);
}
if (count < 0) {
throw new StringIndexOutOfBoundsException(count);
}
// Note: offset or count might be near -1>>>1.
if (offset > value.length - count) {
throw new StringIndexOutOfBoundsException(offset + count);
}
this.value = Arrays.copyOfRange(value, offset, offset+count);
}
public String(int[] codePoints, int offset, int count) {
//略
public String(byte ascii[], int hibyte, int offset, int count) {
//略
// 检查越界
private static void checkBounds(byte[] bytes, int offset, int length) {
if (length < 0)
throw new StringIndexOutOfBoundsException(length);
if (offset < 0)
throw new StringIndexOutOfBoundsException(offset);
if (offset > bytes.length - length)
throw new StringIndexOutOfBoundsException(offset + length);
}
public String(byte bytes[], int offset, int length, String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null)
throw new NullPointerException("charsetName");
checkBounds(bytes, offset, length);
this.value = StringCoding.decode(charsetName, bytes, offset, length);
}
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
//内部构造方法 , 能修改value,外部无法访问
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
主要方法
下面这下方法实现简单:
public int length()
public boolean isEmpty()
public char charAt(int index)
public boolean startsWith() //是否已前缀开头,加上偏移量
public boolean endsWith()
public int indexOf()
public int lastIndexOf()
public String substring() //数学里的[1,5)
public String concat()
public String replace()
public boolean matches() //内部调用了Pattern.matches(regex, this)
public boolean contains()
public String replaceAll(String regex, String replacement)
public static String join( ) //静态连接方法
public String toLowerCase(Locale locale) //小写
public String toUpperCase(Locale locale)
public String trim() //去掉开头和结尾的空格
public char[] toCharArray() //直接内用了 System.arraycopy()
public static String valueOf() //通过构造方法,新创建一个字符串返回,或者使用参数的toString()方法
public native String intern() //跟常量池 有关的 本地方法
这些方法深究深究:
public void getChars(int srcBegin, int srcEnd, char dst[], int dstBegin) ,把String拷贝到特定的char数组中,内部用了System.arraycopy()方法来拷贝。
编码问题getBytes()
- 当需要处理各种各样的编码问题,在处理之前,必须明确“源”的编码,然后用指定的编码方式正确读取到内存中。
- 如不指定编码,此方法使用平台默认的字符集来获取字符串对应的字节数组。首先会使用JVM默认编码,而JVM则取操作系统默认编码(我的win10系统是GBK编码)进行编码。
public byte[] getBytes(String charsetName) ,使用指定的字符集将此字符串编码为一个字节序列,并将结果存储到新的字节数组中。
1 | String str = "中文"; |
输出
1 | defaultCharset:GBK |
比较方法equals()
1 | public boolean equals(Object anObject) { |
public boolean equalsIgnoreCase(String anotherString) :
将这个字符串与另一个字符串进行比较,忽略大小写的考虑。 如果两个字符串的长度相同,两个字符串被认为是相等的,忽略大小写,两个字符串中的相应字符相等则忽略大小写。
比较方法 compareTo()
1 | public int compareTo(String anotherString) { |
public int compareToIgnoreCase(String str) ,比较大小忽略大小写。
hashCode方法
1 | public int hashCode() { |
为什么 是乘 31 ?
在 布洛赫的约书亚 Effective Java 中提及:值 31被选中,因为它是一个奇数。 如果它甚至是乘法溢出,信息会丢失,因为乘以 2等于移位。 使用素数的优势不明显,但它是传统的。 31的一个不错的属性是乘法可以通过移位和减法替换,以获得更好的性能: 31 * i == (i <<5) - i 现代j JVM 自动执行这种优化。
切割方法,split()
1 | public String[] split(String regex, int limit) { |
参考文献
JDK1.8 源码
http://blog.csdn.net/stubbornant/article/details/51535946
http://www.jianshu.com/p/69ad183fefc4
https://segmentfault.com/a/1190000009888357
http://www.importnew.com/18167.html
https://www.zhihu.com/question/55328596
完结。