JDK1.8 HashMap源码解析
JDK源码深揪,JDK1.8版本。
摘要
HashMap 经常用到的 java 内置的数据结构,今天就深入源码瞧瞧,刨一刨。
HashMap 是对 Map 接口的一种哈希表的实现,是 key-value(键-值对),通过 key 可以常数时间内找到 value 。它是非线程安全,如果需要满足线程安全,可以用 Collections 的 synchronizedMap 方法使 HashMap 具有线程安全的能力,或者使用 ConcurrentHashMap。但是 HashMap 不是 Collection 的子集,但是 HashMap 的 key 和value 都可以单独的转换成 Collection子集,比如转换成 Set。HashMap 允许存在 null的,最多只允许一条记录的键为 null,允许多条记录的值为 null。
那我就简单的看一看 HashMap 源码,也是我第一次看整个类,以前都是需要哪个方法 就跳进去 看看,过程又惊喜又痛苦。
源码解析
HashMap继承自AbstractMap,并且实现了Map,Cloneable,Serializable接口。
1 | public class HashMap<K,V> extends AbstractMap<K,V> |
常量
HashMap 的初始容量为16,最大的容量为1073741824(1<<30),当构造函数中没有指定参数时,使用的默认负载因子为0.75f , 使用了基于数组哈希表的结构,数组中每一个元素都是一个链表,把数组中的每一格称为一个桶(bin或bucket)。当HashMap中节点数量超过容量和装填因子的积,会进行扩容操作,扩容后的HashMap容量是之前容量的两倍(左位移操作)。
1 | static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 初始容量 |
HashMap 的扩容及树化过程中会涉及下列常量,当好多的节点(node)被映射在同一个桶(bin)中的时,如果这个桶(bin)的数量小于TREEIFY_THRESHOLD,不会转换成树性结构;如果这个桶(bin)的节点(node)数量大于TREEIFY_THRESHOLD,但是容量(总节点数)却小于MIN_TREEIFY_CAPACITY,则依然使用链表结构进行存储,此时会对HashMap进行扩容,如果容量大于MIN_TREEIFY_CAPACITY就开始进行树形化。
1 | static final int TREEIFY_THRESHOLD = 8; |
成员变量
来看看成员变量, transient 此成员变量不可序列化。 都知道 HashMap 是数组链表(+红黑树),Node<K,V>[] table 是哈希桶数组。对于红黑树抽空搞一搞。
1 | transient Node<K,V>[] table; |
节点
HashMap 的节点 , 第一个是链表节点,第二个是红黑树节点。
1 | //链表节点 |
构造函数
HashMap 有四个构造函数,主要涉及两个成员变量loadFactor(负载因子)threshold(下一次调整大小的阈值(capacity * load factor))。构造函数并不会创建空间,第一次put操作才会创建空间,懒加载过程。
1 | public HashMap(int initialCapacity, float loadFactor) { |
Hash 算法 和 扩容过程
Hash 算法
hash算法三个步骤:
- 用 key 的 hashCode() 获取 hash 值。
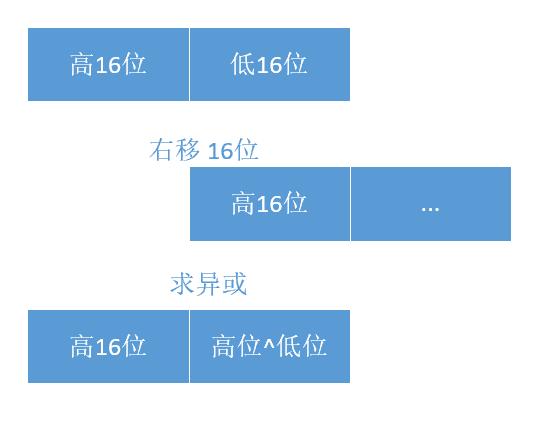
- 无符号右移16位(无符号,空位补0,一共32位),然后异或(
^)运算。这样可以避免只靠低位数据来计算哈希时导致的冲突,计算结果由高低位结合决定,可以避免哈希值分布不均匀。 - 最后用table的长度求模(h%table.length)。比如,在获取和插入方法getNode(),putVal() 都有求模运算,只不过用与(
&)运算来代替模运算来提高效率。
1 | //hash 方法 |
图解,图片地址http://blog.csdn.net/u011240877/article/details/53351188

扩容过程
这篇文章(http://blog.csdn.net/fan2012huan/article/details/51088211)中有笔者详细实验,详细记录了扩容过程,但是我这里就刨一刨代码是怎么实现的。
直接看代码。
1 | /** |
公共方法
//返回size。
public int size()
// 是否为空。
public boolean isEmpty()
// 获取value,里面调用了final getNode(int hash, Object key)方法。
public V get(Object key)
// 是否存在key,里面调用了final getNode(int hash, Object key)方法。
public boolean containsKey(Object key)
// 与key相关联的上一个value,如果不存在key,是新加key-value,则返回null。
public V put(K key, V value)
// 将指定map的所有映射复制到此map。这个跟用map构造函数一样。
public void putAll(Map<? extends K, ? extends V> m)
// 删除key对应的key-value,删除成功返回上一个value值。
public V remove(Object key)
// 删除所有节点
public void clear()
//value 是否存在
public boolean containsValue(Object value)
// 返回key的set集合
public Set
// 返回value的Colection集合 , 跟AbstractMap 里变量 values 有关。
public Collection
// 返回key-value 的MapEntry
public Set<Map.Entry<K,V>> entrySet()
jdk1.8 扩展的方法,都是重写了Map 接口
// 重写Map接口的方法,获取value ,不存在则得到默认值
public V getOrDefault(Object key, V defaultValue)
// 重写Map接口的方法,如果指定的key尚未与value相关联(或映射到{@code null}),则将其与给定value相关联并返回{@code null},否则返回当前value。
public V putIfAbsent(K key, V value)
// 删除节点 , 里面返回了节点并且判断了是否为空。
public boolean remove(Object key, Object value)
// 仅当当前映射到指定的oldValue时,才能替换成newValue。
public boolean replace(K key, V oldValue, V newValue)
// 替换key 对应得value,返回以前的value 或 null。
public V replace(K key, V value)
// 如果指定的key尚未与value相关联(或映射到null),则尝试使用给定的映射函数计算其value,并将其输入到此映射中,除非为null。 返回与指定key相关联的当前(现有或计算)value,如果计算值为空,则为null。
public V computeIfAbsent(K key, Function<? super K, ? extends V> mappingFunction)
后面是一些 三个迭代器(key,value,entry) 和 TreeNode 相关代码,不看了,目前还没兴趣往下看。
参考文献
JDK1.8 源码
https://tech.meituan.com/java-hashmap.html
http://blog.csdn.net/fan2012huan/article/details/51088211
http://blog.jrwang.me/2016/java-collections-hashmap/
http://blog.csdn.net/u011240877/article/details/53351188
完结。